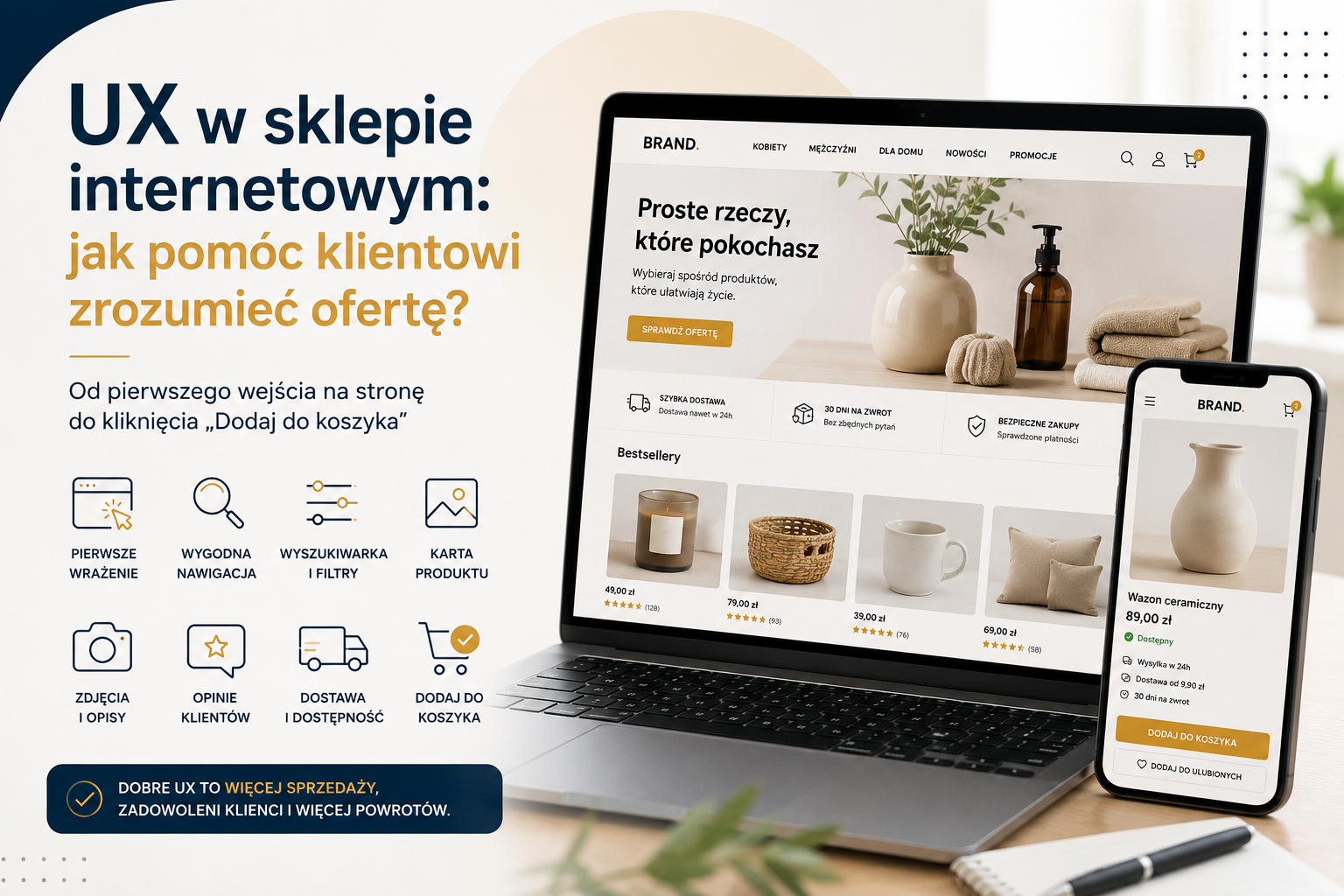
Algorytmy to nie wszystko. Jak tworzyć skuteczne treści dla różnych mediów społecznościowych?
Tekst podkreśla, że skuteczna komunikacja w mediach społecznościowych wymaga dostosowania treści do specyfiki każdej platformy, ponieważ różnią się one odbiorcami, formatami i algorytmami. Facebook sprzyja budowaniu relacji, LinkedIn wzmacnia ekspercki wizerunek, Instagram stawia na estetykę i emocje, TikTok na autentyczne, krótkie filmy, a YouTube na edukację i długoterminowe budowanie zaufania. Najlepsze efekty przynoszą wartościowe, autentyczne treści, regularna analiza wyników oraz strategia oparta na budowaniu relacji i zaufania, a nie wyłącznie na sprzedaży.


.png)